Giả sử, chúng ta muốn thiết kế một hệ thống lưu trữ hồ sơ nhân viên. Mỗi hồ sơ sẽ có một key (khóa) để định danh bằng cách dùng số điện thoại. Chúng ta muốn hệ thống đó phải thực hiện các thao tác sau một cách hiệu quả:
- Thêm mới một số điện thoại và thông tin hồ sơ nhân viên tương ứng.
- Tìm kiếm một số điện thoại và lấy các thông tin đính kèm.
- Xóa một số điện thoại và tất cả các thông tin liên quan tới nó.
1. Tư tưởng của Hashing
Vậy với các yêu cầu trên, chúng ta có thể nghĩ sẽ thiết kế hệ thống sử dụng các cấu trúc dữ liệu như dưới đây để lưu trữ số điện thoại kèm thông tin tương ứng:
- Một Array (mảng) lưu trữ số điện thoại và hồ sơ.
- Một Linked List (danh sách liên kết) lưu trữ số điện thoại và hồ sơ.
- Một Balanced Binary Search Tree (cây tìm kiếm nhị phân cân bằng) sử dụng số điện thoại làm key (khóa).
- Một Direct Access Table (sử dụng trực tiếp khóa làm chỉ mục trong mảng).
Với Array và Linked List, trong thao tác tìm kiếm thì chúng ta cần phải tìm kiếm theo kiểu tuyến tính (Linear Search). Nếu danh sách đã được sắp xếp, số điện thoại có thể được tìm theo Binary Search, mà có độ phức tạp thời gian là O(log n). Nhưng chúng ta phải trả giá cho thao tác thêm mới và xóa, vì phải luôn duy trì thứ tự sắp xếp.
Với Balanced Binary Search Tree, tất cả các thao tác tìm kiếm, thêm mới, xóa có thể được đảm bảo trong thời gian O(log n).
Với Direct Access Table, chúng ta sẽ tạo ra một mảng lớn và sử dụng số điện thoại làm chỉ mục trong mảng. Mỗi mục trong mảng sẽ là NIL (0 hoặc null) nếu không có thông tin lưu trữ. Với cấu trúc dữ liệu này, Time Complexity sẽ tốt nhất so với tất cả các cấu trúc trên, chúng ta có thể thực hiện tất cả các thao tác trong thời gian O(1).
Giải pháp Direct Access Table trong thực tế có rất nhiều hạn chế. Hạn chế dễ thấy nhất là bộ nhớ cần thiết để lưu trữ sẽ rất lớn.
Hashing là một giải pháp để thay thế cho tất cả các cấu trúc dữ liệu trên khi làm thực tế. Hashing là một kỹ thuật cải tiến hơn so với Direct Access Table.
Ý tưởng của Hashing là phân phối các cặp khóa/giá trị trên một mảng. Nó sử dụng một hash function (hàm băm) để chuyển đổi các khóa có giá trị lớn thành giá trị nhỏ hơn và sử dụng số nhỏ hơn đó làm chỉ mục trong một bảng gọi là hash table (bảng băm).
2. Hash function
Hash function là một hàm ánh xạ một dữ liệu có kích thước tùy ý (một số nguyên lớn, một chuỗi,…) thành một số nguyên nhỏ để có thể sử dụng làm chỉ mục trong hash table. Giá trị trả về của hash function có thể gọi là hash values, hash codes hoặc đơn giản là hashes.
Một Hash function tốt phải đạt được các yêu cầu sau:
- Dễ tính toán
- Phân phối đều: Giá trị trả về từ hash function sẽ giúp phân phối đều các entries trên hash table, tránh bị phân thành các cụm.
- Tránh ít va chạm (collisions): Va chạm xảy ra khi các cặp phần tử được ánh xạ tới cùng một hash codes.
Lưu ý: Dù việc cài đặt hash function tốt đến đâu đi chăng nữa, thì việc xảy ra va chạm (collisions) là điều không thể tránh khỏi. Vì vậy để duy trì một performance tốt cho hash table, điều quan trọng là phải xử lý các collisions thông qua các kỹ thuật khác nhau.
3. Hash table
Hash table (bảng băm) là một cấu trúc dữ liệu sử dụng mảng để lưu trữ các cặp khóa/giá trị. Mỗi vị trí trong mảng gọi là một bucket, có thể null, chứa một, hoặc chứa nhiều cặp khóa/giá trị. Nó sử dụng hash function (hàm băm) để tính toán một index trong mảng để chèn hoặc tìm kiếm phần tử.
Bằng cách cài đặt một hash function tốt, chúng ta sẽ có một hash table hoạt động với performance tốt. Theo các giả thiết lý tưởng, thời gian trung bình cần thiết để tìm kiếm một phần tử trong hash table là O(1).
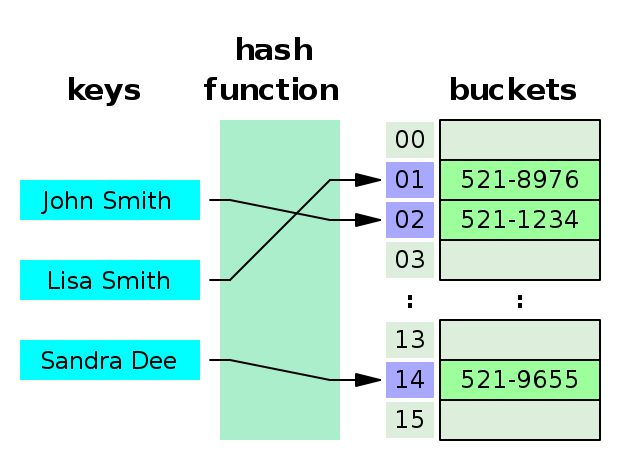
Giải thích hình minh họa:
- Ta cần lưu trữ thông tin của 3 người, với key (khóa) là tên, còn giá trị là số điện thoại:
- John Smith: 521-1234
- Lisa Smith: 521-8976
- Sandra Dee: 521-9655
- Giá trị Hash của 3 người này lần lượt là: 1, 2 và 14.
- Sau khi tính được giá trị Hash của 3 người, ta lưu vào các bucket tương ứng là 1, 2 và 14.
Nếu các kết quả của hàm hash được phân bố đều, các bucket sẽ có kích thước xấp xỉ nhau. Giả sử số bucket đủ lớn, mỗi buckets sẽ chỉ có một vài phần tử trong chúng. Điều này làm cho việc tìm kiếm rất hiệu quả.
4. Độ phức tạp
Gọi:
- n là số phần tử ta cần lưu trong Hash table
- k là số bucket
Giá trị α = n / k được gọi là load factor (số phần tử trung bình được lưu ở mỗi bucket).
Khi load factor nhỏ (xấp xỉ 1), và giá trị của hash function phân bố đều, thì độ phức tạp của các thao tác trên Hash table là O(1).
5. Collision Handling
Vì hash function giúp chuyển đổi một khóa có giá trị lớn thành một số nhỏ nên sẽ có khả năng 2 khóa sẽ có cùng một giá trị băm (hash codes). Collision là một tình huống khi thêm mới một phần tử vào một vị trí mà đã tồn tại một phần tử khác trong hash table, lúc này ta phải xử lý va chạm bằng một số kỹ thuật:
5.1. Separate Chaining
Tư tưởng là cài đặt thêm các Linked List (danh sách liên kết) ở các bucket để lưu trữ các phần tử có cùng giá trị hash code.
Ưu điểm:
- Kỹ thuật này cài đặt đơn giản
- Hash table sẽ khó bị lấp đầy, vì các giá trị có cùng hash code ta sẽ nối thêm vào linked list.
- Nó chủ yếu được sử dụng khi không biết có bao nhiêu và tần suất các khóa có thể được chèn hoặc xóa.
Nhược điểm:
- Tốn bộ nhớ vì một phần của hash table không bao giờ được sử dụng, và tốn thêm cả bộ nhớ lưu trữ cho linked list.
- Nếu Linked List quá dài, thì thời gian tìm kiếm có thể là O(n) trong worse case.
- Hiệu suất của bộ nhớ cache không tốt.
Độ phức tạp:
Time Complexity để thực hiện các thao tác search/insert/delete là: O(1 + α)
- 1 là thực hiện hash function và truy cập tới vị trí trong hash table
- α là duyệt qua danh sách ở mỗi vị trí.
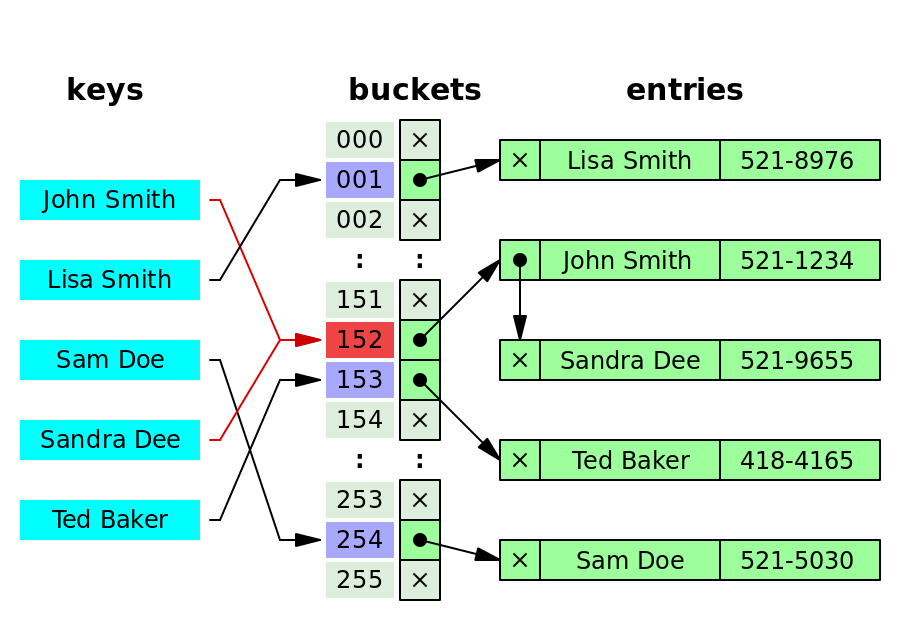
Giải thích hình minh họa:
- Mỗi bucket là 1 danh sách liên kết
- John Smith và Sandra Dee cùng có giá trị hàm hash là 152, nên ở bucket 152, ta có 1 danh sách liên kết chứa 2 phần tử.
5.2. Open Addressing
Tư tưởng của Open Addressing là khi xảy ra Hash collision, ta lưu vào một vị trí tiếp theo trong hash table. Tức là, hash table phải đủ vị trí để lưu tất cả các phần tử. Vì vậy, kích thước của hash table luôn >= tổng số khóa, hay Load factor phải nhỏ hơn 1.
Việc tìm vị trí tiếp theo để lưu khóa có thể được thực hiện bằng một số cách sau:
- Linear Probing
- Quadratic Probing
- Double Hashing
Minh họa việc tìm vị trí tiếp theo của khóa theo Linear Probing:

Trong hình minh họa:
- John Smith và Sandra Dee đều có giá trị Hash là 152. Vì ta đã lưu John Smith vào bucket 152, nên ta buộc phải lưu Sandra Dee vào bucket 153.
- Ted Baker có giá trị Hash là 153, nhưng lúc này bucket 153 đã lưu thông tin của Sandra Dee, nên ta phải lưu giá trị của Ted Baker vào bucket 154.
Đọc thêm:
https://en.wikipedia.org/wiki/Hash_table
https://www.hackerearth.com/practice/data-structures/hash-tables/basics-of-hash-tables/tutorial/
